PIXER: Enhancing Visual Odometry with Reliable Pixel Masking
Conference on Robots and Vision (CRV) 2026

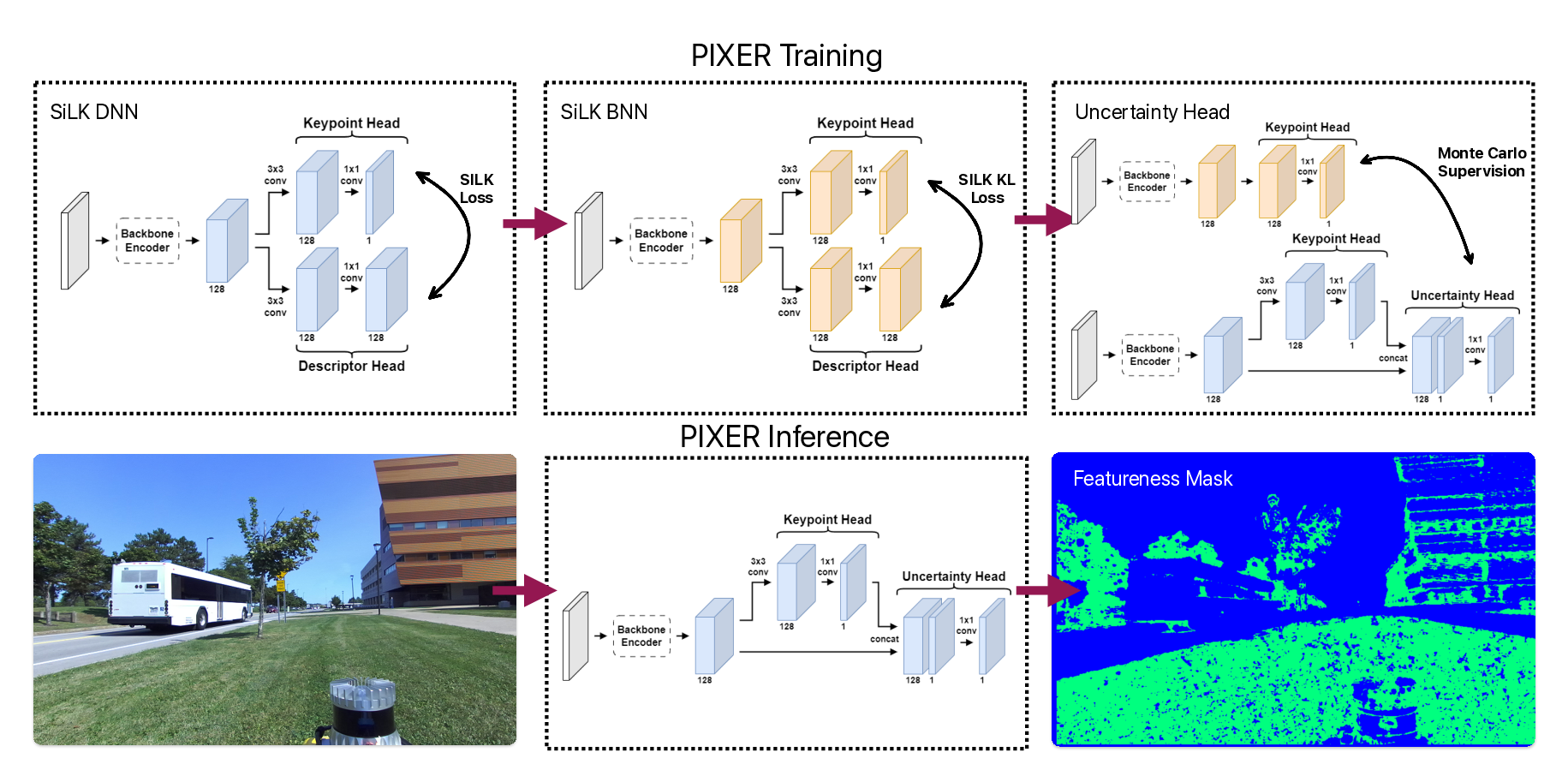
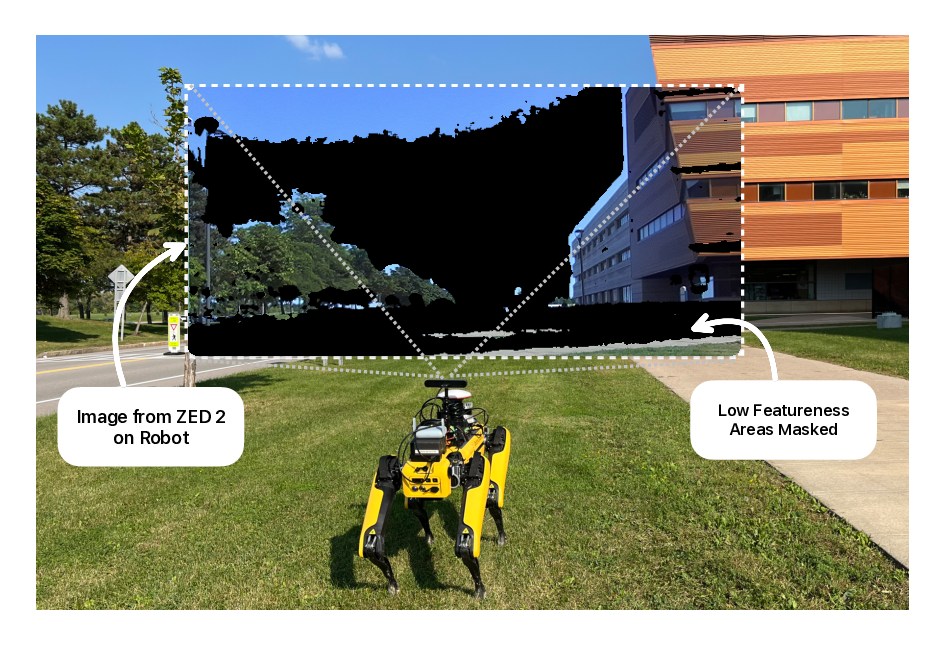
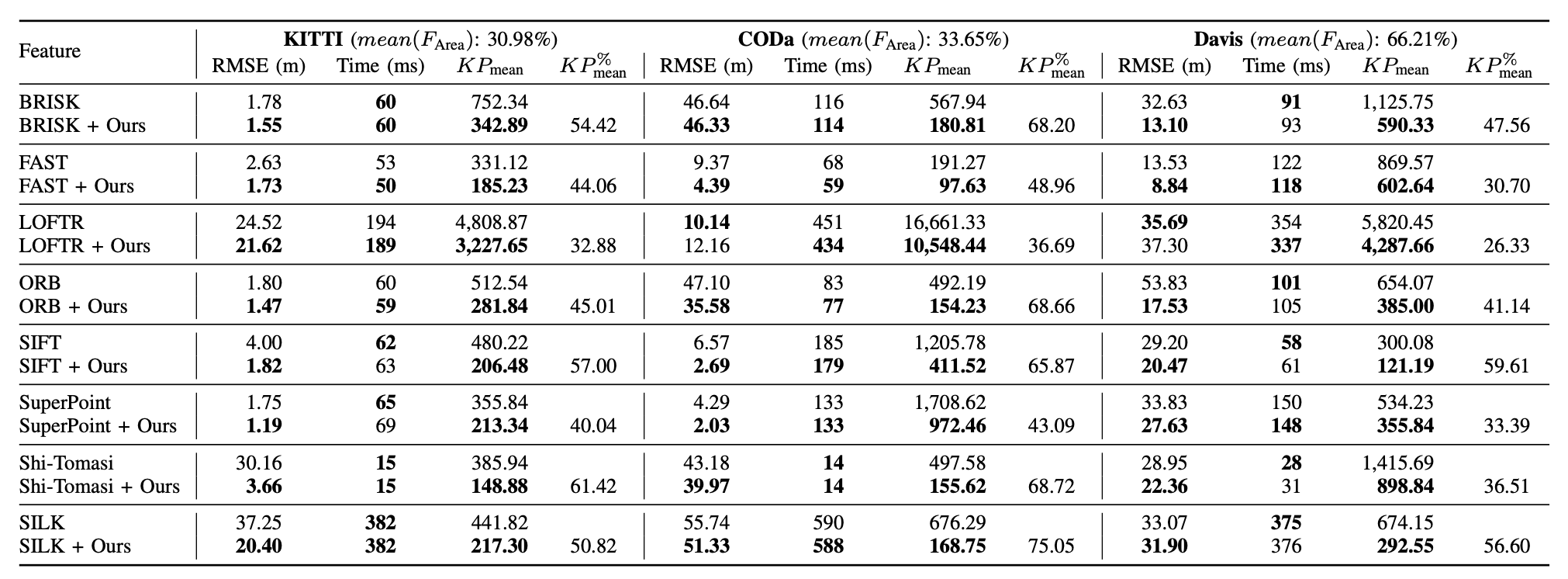
PIXER is a lightweight, self-supervised feature utility network trained with a Bayesian formulation, designed to predict a pixel-wise Reliability score indicating how likely a feature keypoint at that pixel will survive matching. Top-left: raw keypoints from two conventional detectors—SIFT (blue) and ORB (green)—illustrate the well-known disagreement between handcrafted methods. Top-right: after passing the same detections through PIXER, the reliability mask F removes low-utility points (red), leaving a compact set of high-value features. Bottom: dense reliability heatmaps are produced in a single forward pass; thresholding this map yields mask F . When this mask is applied as a pre-processing filter, any downstream detector/descriptor benefits—cutting the number of keypoints by roughly half and reducing drift in visual-odometry pipelines.